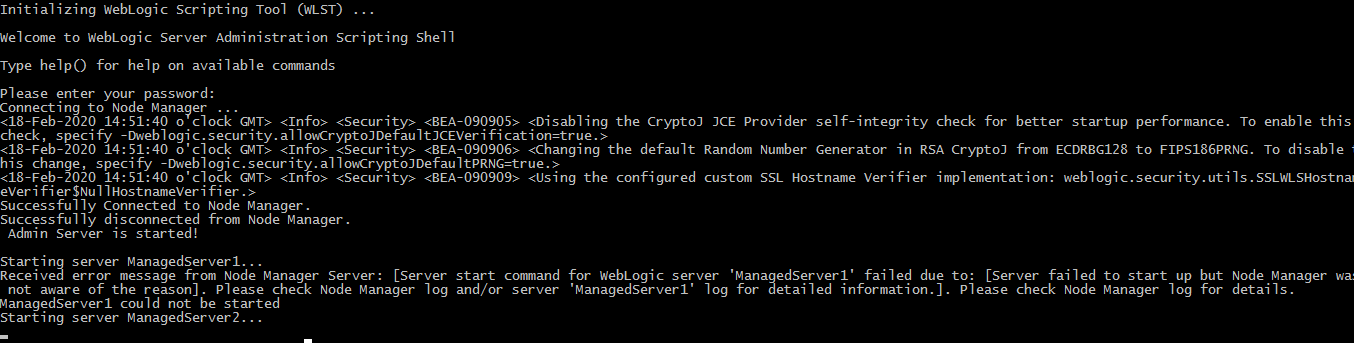
We just refreshed our test environment from live. Now used stop_all_servers.bat to stop all servers. All servers successfully stopped.
However upon restarting servers the script is stuck at Starting server ManagedServer1….
Any idea what could be the reason. Looking at the logs it shows
The server 'ManagedServer1' with process id 21880 is no longer alive; waiting for the process to die.
Best answer by Srikanth
Hi Bhavesh,
Are you on IFS Apps 9?
Are both TEST and PROD instances on the same IFS Patch version?
You can try restarting the TEST Application (Windows) Server to see if that fixes your issue quickly. I am attaching a quick guide on how to restart IFS Services in Apps 9 safely.
If server restart doesn’t work, you can reconfigure TEST applications to reset all the services and ports.
Are both TEST and PROD instances on the same IFS Patch version?
You can try restarting the TEST Application (Windows) Server to see if that fixes your issue quickly. I am attaching a quick guide on how to restart IFS Services in Apps 9 safely.
If server restart doesn’t work, you can reconfigure TEST applications to reset all the services and ports.
How long has it been running? Starting and stopping of ManagedServers can take a horribly long time (especially when its production and everyone is waiting on you). I have seen it take over 10 minutes.
If really stuck, i would probably reboot the server (if on seperate box to Live), then start each service one by one. Ensuring Admin Server is running before running ManagedServer starts. I use start_as_server.cmd and enter nothing for the ManagedServer name, this will then start Admin. Check servers, then start_as_server.cmd again, this time specifying ManagedServer1.
This is test instance fortunately. The windows server has 3 test IFS instances running, one of which was recently upgraded to UPD 16. Now I am doing same for another instance of IFS. Before running patching I always make sure stop_all_servers and start_all_servers scripts are working and have been stuck on start_all_server since 1 hours now. Logs does not reveal much.
Logs from managedserver
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256m; support was removed in 8.0 <18-Feb-2020 14:52:02 o'clock GMT> <INFO> <NodeManager> <The server 'ManagedServer1' with process id 9152 is no longer alive; waiting for the process to die.> <18-Feb-2020 14:52:02 o'clock GMT> <FINEST> <NodeManager> <Process died.> <18-Feb-2020 14:52:02 o'clock GMT> <INFO> <NodeManager> <Server failed during startup and will be retried> <18-Feb-2020 14:52:02 o'clock GMT> <FINEST> <NodeManager> <get latest startup configuration before deciding/trying to restart the server> <18-Feb-2020 14:52:02 o'clock GMT> <INFO> <NodeManager> <Server failed but will not be restarted because the maximum number of restart attempts has been exceeded> <18-Feb-2020 14:52:02 o'clock GMT> <FINEST> <NodeManager> <runMonitor returned, setting finished=true and notifying waiters>
Check for any running <test instance in question> specific Processes running under Windows Task Manager and End them. Try starting the IFS servers in the order specified in the document attached in my previous post.
there should be more detailed error. Check admin server logs and nodemanager logs as well.
Stop all servers using the script again and try to start over.
Check whether any processes running from this environment's managed server location - just to make sure no hanging process in task manager.
Additionally attempt to start it again after 15 minutes or so.
AS logs
####<18-Feb-2020 15:06:48 o'clock GMT> <Error> <EJB> <PCS-CHE-IFST-1> <ManagedServer2> <[ACTIVE] ExecuteThread: '0' for queue: 'weblogic.kernel.Default (self-tuning)'> <<WLS Kernel>> <> <38419347-910f-42a9-9649-4ebc9a23f04e-00000030> <1582038408192> <BEA-010079> <An error occurred while attempting to receive a message from JMS for processing by a Message-Driven Bean: javax.jms.JMSException: [JMSPool:169812]The pooled JMS session is enlisted in another transaction and may not be used elsewhere. The exception is : javax.jms.JMSException: [JMSPool:169812]The pooled JMS session is enlisted in another transaction and may not be used elsewhere. at weblogic.deployment.jms.JMSExceptions.getJMSException(JMSExceptions.java:22) at weblogic.deployment.jms.WrappedTransactionalSession.enlistInTransaction(WrappedTransactionalSession.java:205) at weblogic.deployment.jms.WrappedMessageConsumer.receive(WrappedMessageConsumer.java:198) at weblogic.ejb.container.internal.TokenBasedJMSMessagePoller$1.run(TokenBasedJMSMessagePoller.java:316) at weblogic.ejb.container.internal.TokenBasedJMSMessagePoller$1.run(TokenBasedJMSMessagePoller.java:313) at weblogic.security.acl.internal.AuthenticatedSubject.doAs(AuthenticatedSubject.java:363) at weblogic.ejb.container.internal.JMSConnectionPoller.doPrivilegedJMSAction(JMSConnectionPoller.java:1982) at weblogic.ejb.container.internal.TokenBasedJMSMessagePoller.processOneMessage(TokenBasedJMSMessagePoller.java:312) at weblogic.ejb.container.internal.TokenBasedJMSMessagePoller.run(TokenBasedJMSMessagePoller.java:137) at weblogic.work.SelfTuningWorkManagerImpl$WorkAdapterImpl.run(SelfTuningWorkManagerImpl.java:553) at weblogic.work.ExecuteThread.execute(ExecuteThread.java:311) at weblogic.work.ExecuteThread.run(ExecuteThread.java:263)
If not already done so, it might be worth checking the installation logs from update16, in case anything went wrong.
UPD 16 is not applied to the test instance yes, I am attempting to apply. Like I said it is different test instance where I am about to start applying UPD 13 - 16. But before that I always test start stop scripts.