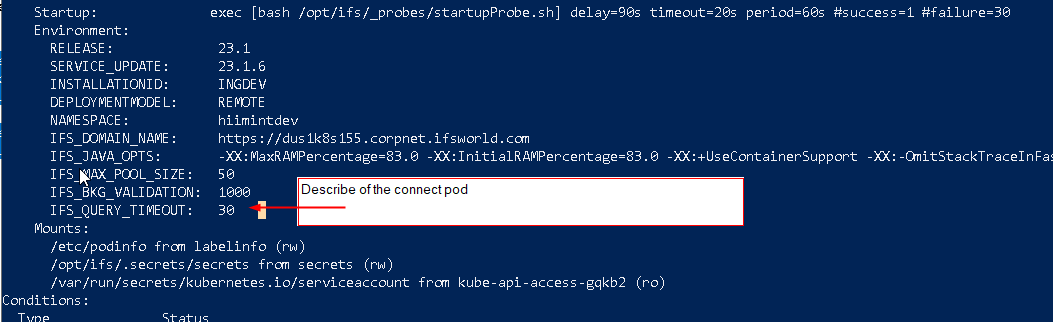
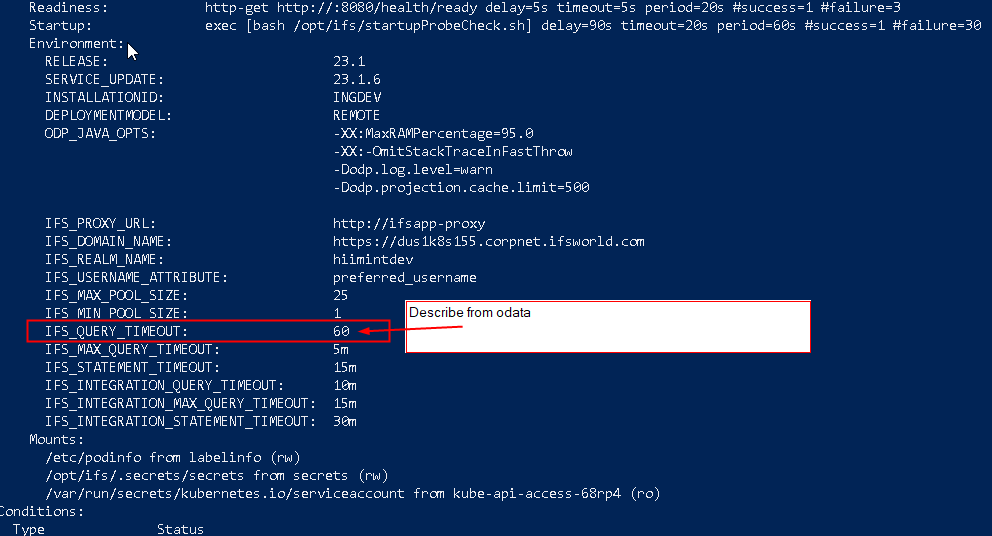
We have an interface, sending in 1000s of messages through connect to application messages, and about 10 - 15% ends with error:
ExecutionException from Sender thread
Caused by: ifs.fnd.connect.senders.ConnectSender$PermanentFailureException: Request has been aborted or timed out
Caused by: ifs.fnd.base.UserAbortException: Request has been aborted or timed out
Caused by: java.sql.SQLTimeoutException: ORA-01013: user requested cancel of current operation
Caused by: oracle.jdbc.OracleDatabaseException: ORA-01013: user requested cancel of current operation
We have three connect pods set to 1 minute time out.
What could be a reason for this to happen?
We are on 23R1 SU6.