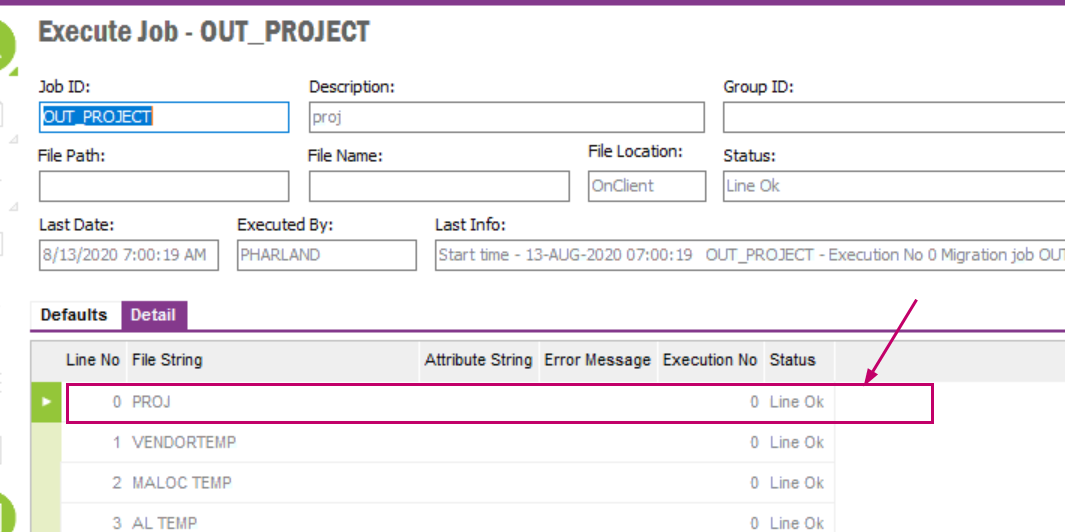
We have a few consultant designed interfaces at present, which work well but I would like to start creating simple ones myself.
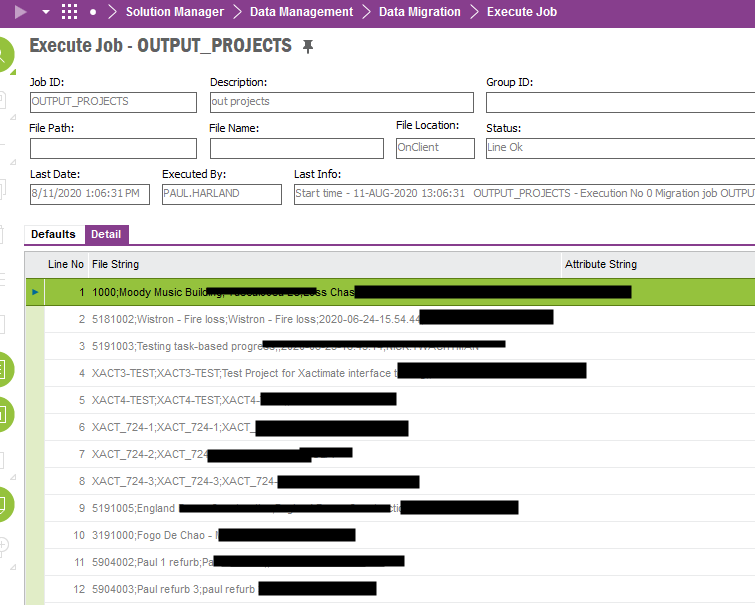
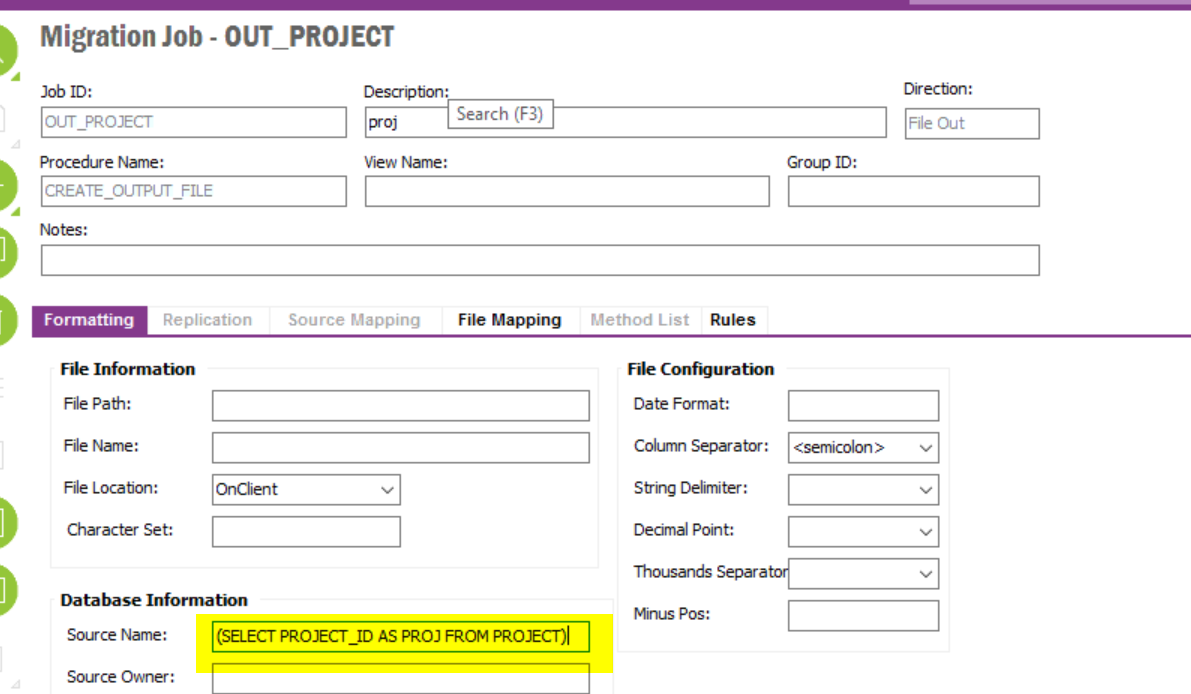
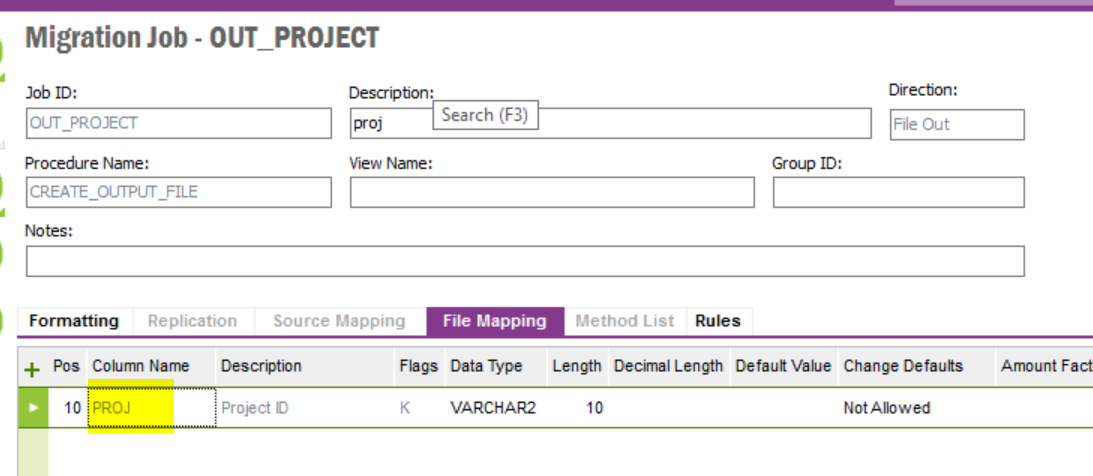
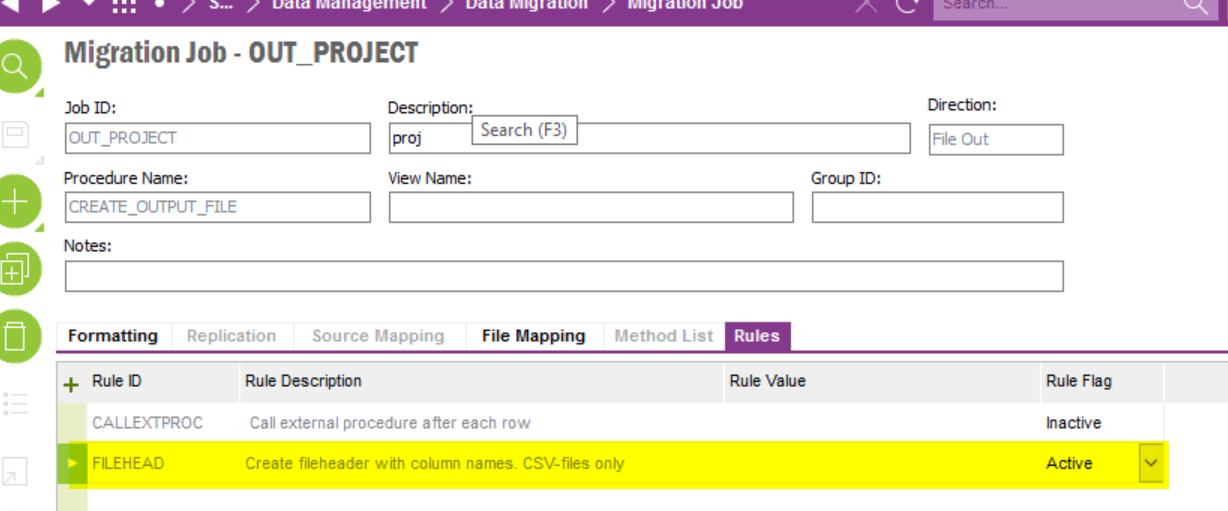
For this example, I need to create a CSV output on a scheduled basis, with the output file having data placed in columns specific to my needs.
Is there a guide on easiest way to achieve this?
Possibly in the future, may also use an input file but think I will be using external file loads and running them manually at the moment.
Thanks