Hi,
The MainServer logs are continuously growing and causing the drive hosting IFS Application to go out of space with the following repetitive errors:
####<Jun 6, 2021, 6:16:29,948 PM PDT> <Error> <com.ifsworld.jms.IfsWebStreamsTopicBean> <DIVIFSAPP02> <MainServer1> <[ACTIVE] ExecuteThread: '27' for queue: 'weblogic.kernel.Default (self-tuning)'> <<anonymous>> <BEA1-55E98D048B51F37E17FE> <ea976e53-587f-48f7-854f-00e338b9f183-6d5822c7> <1623028589948> <[severity-value: 8] [rid: 0] [partition-id: 0] [partition-name: DOMAIN] > <BEA-000000> <null
java.lang.NullPointerException
>
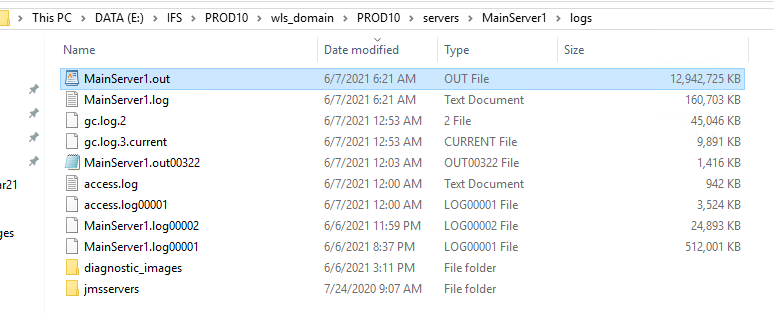
The MainServer1.out log can grow up to 35 GB before I manually clear it out:
Has someone come across the same issue. I noticed this happens in other non-production environment too but the logs aren’t growing as big & fast, as just a few users access it.
Thanks in advance!