")

We are currently implementing a workflow that allows us to create customer sales orders.
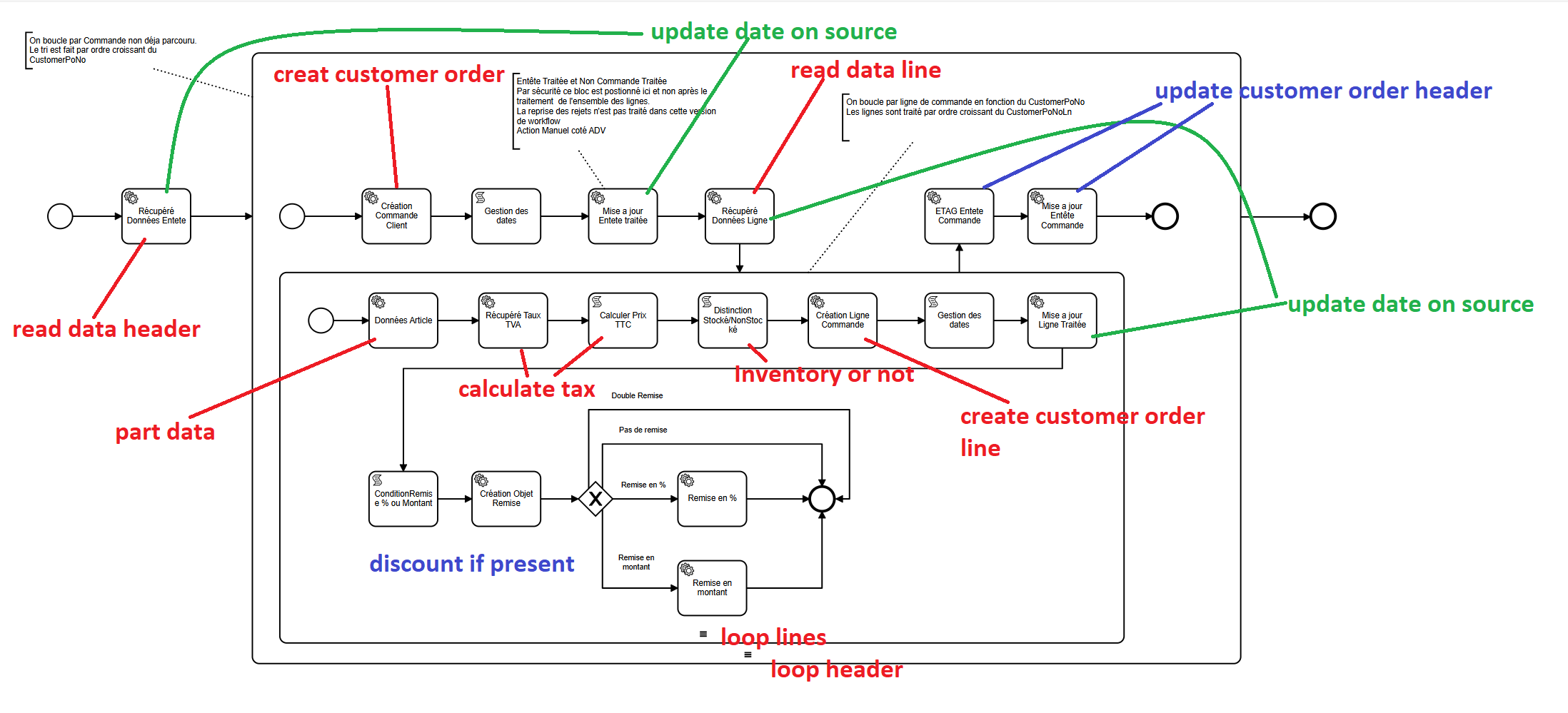
Tests on a small scale are okay and we are happy.
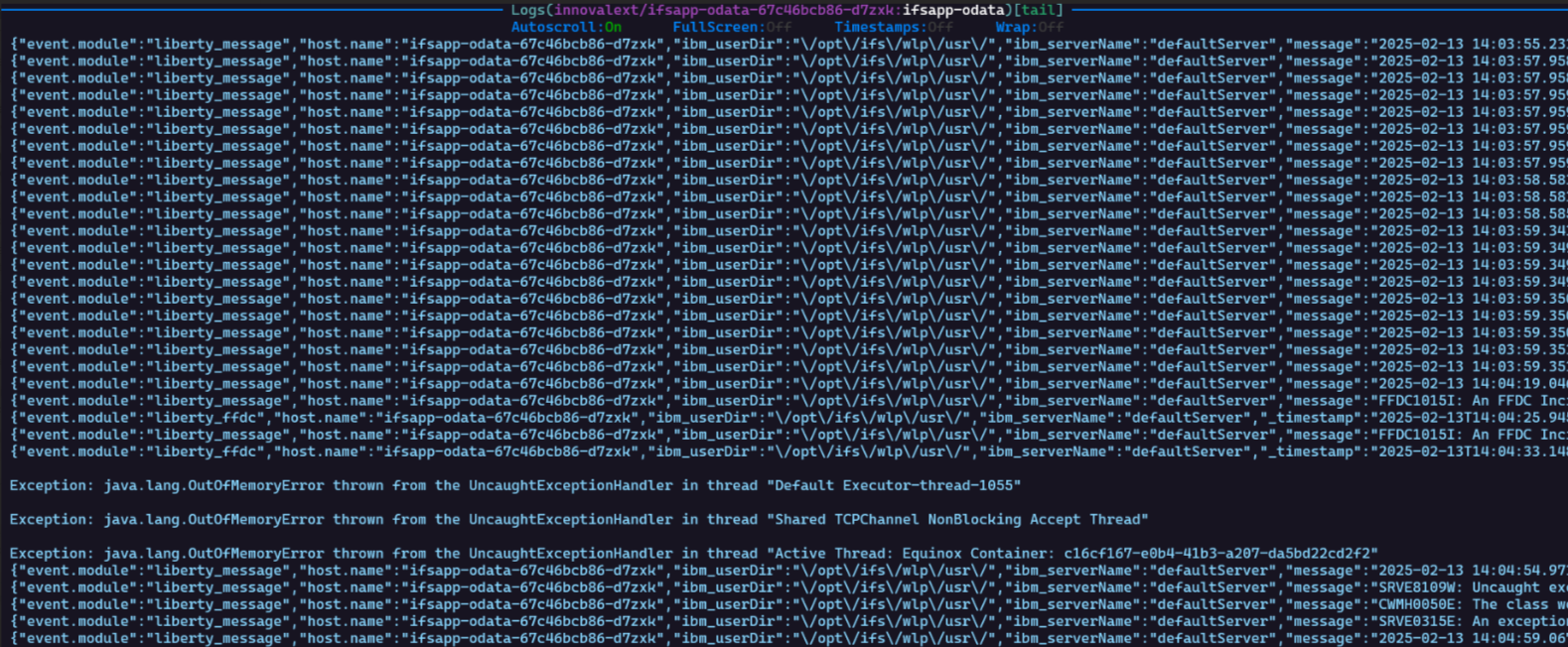
However, as soon as we move to a larger scale, the workflow crashes without an error.
The dataset is composed of the same order that we create X times, so we know that we have no functional problems because iterating 30 creations, for example, is okay, but not 100.
We have already limited the return of the projection as much as possible by using $select to retrieve only the desired columns.
We have not exceeded the line reading limit per projection (10.000) (at most we read 5000 lines) and we don't think we have a problem with CASCADE_LIMIT because we set it to 250,000 for testing.
We are more inclined towards a memory/CPU/space limit for the one of the pods.
Do you have any knowledge of documentation or experience to parameterize the recommended memory or CPU or disk size?
Thank’s in advance

")