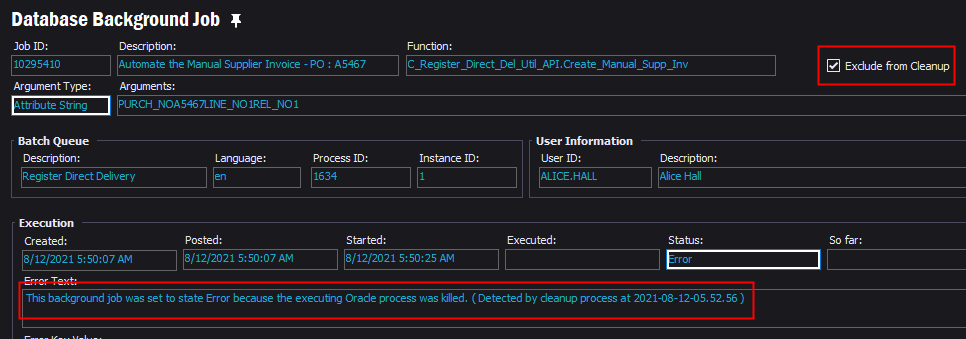
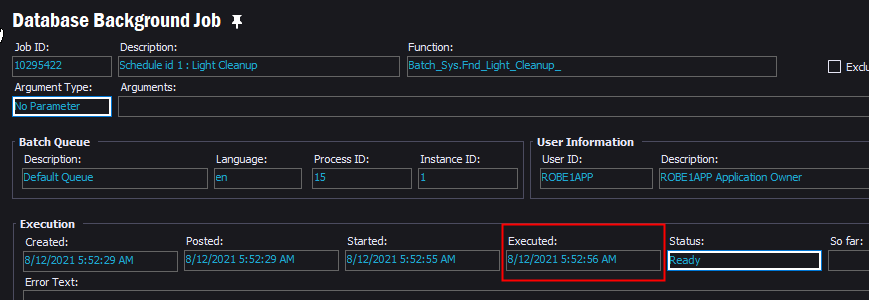
Has anyone had a custom background job killed by a schedule Light Cleanup? The job is marked as “Exclude from Cleanup,” we did this after it happened the first time and thought it would keep it from happening again.
This background job was executed at the exact time listed in the error of the above background job.
These are in two different queue’s as we’ve moved a majority of our custom jobs into their own to keep jobs processing.
On another note, how often are you running the Light Cleanup job? What’s the suggested time frame?
We are on IFS10 UPD10.
Page 1 / 1
Hi Sara,
Do you have any other evidence to suggest that the custom background job was infact killed by the schedule Light Cleanup? ( Other than the two jobs ran at the exact same time) . Can this behavior be re-created on demand? If yes, I suggest creating a case if you already have not..
The answer to your second question is, Scheduling recommendation for Light Cleanup is Every tenth minute.
I don’t have any other evidence other than the time stamps. That piece has been consistent each time this has happened. I can try to re-create this on demand in another environment. I’ll have to do the steps to kick off the custom background job then manually run the cleanup job to see if the same thing happens. But the error message does say it was killed by a cleanup process. Are there any other scenarios in which a background job would be killed?
We have ours running every 10 minutes, wasn’t sure if that was the norm or not.
Hi @SaraCrank ,
Light cleanup job check whether the background job has connected database session at the time of execution. If there is no connected session then that will detected by the light clean up job and changed it the state to error.
I advice to check the existence of database session at the time of background job execution. You may check that in PL SQL sessions window. Database sessions for long running jobs are disappeared after a while of execution when there is a memory issue. Eg: PGA memory issue. You can check the oracle alert log to identify that.
“Exclude from Cleanup” will be helpful for you to avoid detecting by the clean up job. However that will keep the background jobs in ‘Executing’ state if there is a issue with background job as I mentioned above. Therefore it is necessary to identify the root cause of this. You may check whether you have any executing state jobs for the give custom job.
Every 10 minutes seems way to frequent to me.
Ours is set for every 4 hrs, we don’t notice problems with that much slower pace. We have higher frequency jobs to see if there are things to do (check for new parts transferred from PLM every 5 mins, check for new invoices to process every hour, etc). But haven’t found the need to remove things that frequently.
@ShawnBerk - I was thinking the same thing. According to the link above, the light cleanup is doing this: Light cleanup removes data from Background Jobs, Foundation1 Session information and replicates IAL objects. What happens if that information isn’t cleaned up every 10 minutes?
@SaraCrank
Worst case, I think...the info just sits there. The background job info being there four hours rather than 10 minutes to me is useful for troubleshooting. Yes, it means there are more to sift through, but for me, more info is better for forensics. The Foundation1 Session info could be problematic if you were close to license limits or you had lots of individuals who hop around from one terminal to another to login and there is a delay in their session cleanup. For that one, we have a separate job we created and run every 2 minutes to kill any idle sessions that are causing blocks.
For the IAL refresh, we have those on their own schedule most of the time and don’t rely on the Light Cleanup to do the work.
Sorry to butt in, by I am confused by the IAL mention… I thought IAL queries ran on demand or on a schedule defined by the user. Why would Light Cleanup be doing anything with IAL query execution? What exactly is an “IAL refresh”?
Or, if it is just pure “cleanup”, what needs to be cleaned up for IAL queries?
I really like IALs but we are just getting started with them -- I’d like to understand their holistic system impact before we lean on them more. Thanks for any insights!
Thanks,
Joe Kaufman
@sutekh137
That is a very good question for one of the R&D guys, I don’t know either.
“I really like IALs “
Don’t get too attached to them, they are removed in IFS Cloud. We still haven’t got our hands on a Cloud environment to figure out the new tech that replaces the concept.
@sutekh137
That is a very good question for one of the R&D guys, I don’t know either.
“I really like IALs “
Don’t get too attached to them, they are removed in IFS Cloud. We still haven’t got our hands on a Cloud environment to figure out the new tech that replaces the concept.
Unless the replacement is serviceable, this would be another reason we wouldn’t be moving to the Cloud any time soon. *smile* We will be using IALs extensively for Lobby Data Elements and Quick reports, and we are just getting started on our implementation.
Though, considering IALs are really just hand-rolled Materialized Views, I would guess IFS has simply taken more advantage of those in native Oracle? Time will tell, I suppose.
Thanks,
Joe Kaufman
@SaraCrank
Back to your original problem...to troubleshoot, especially if you can manage to recreate the situation, extending the Light Cleanup frequency ten-fold in the test environment should easily help you see if that is stepping on your job or the job is not executing but is gone before you get a chance to see what happened.
If you can’t recreate it, you could still consider extending the cleanup task frequency in PROD for a bit to monitor the background job problem. If everyone who needs to know, knows why you’ve done it and the possible effects, it should be manageable even if you don’t have the other jobs we have filling gaps.
I don’t see any wrongdoing on the part of the light cleanup process here. This probably isn’t what killed the session; it’s just notifying you that it found the session was already killed. It’s just the messenger. Don’t shoot the messenger.
A background job is both an IFS application concept and something that runs inside Oracle. Both systems track the background job in their own ways:
A background job is stored in TRANSACTION_SYS_LOCAL_TAB. This is an IFS table that sits on disk. It persists when the database is shut down.
An Oracle session is stored in V$SESSION. This is an Oracle table that resides in memory. It goes away when the database is shut down.
When a job starts, IFS flips TRANSACTION_SYS_LOCAL_TAB.STATE from 'Posted' to 'Executing' and writes the SID and SERIAL# columns corresponding to the database session in V$SESSION. Those two columns are the link between the IFS and Oracle perspectives of the job.
When these two tables get out of sync is when you run into trouble. You might shut down the database while a job is running, and when you start it up, the job still reports as 'Executing' even though the job is no longer running in Oracle.
The same thing happens when the session dies, like if it’s killed by an administrator with ALTER SYSTEM or if the process dies of natural causes like running out of PGA space.
The cleanup process comes along and reads all the 'Executing' jobs in TRANSACTION_SYS_LOCAL_TAB and compares their (SID, SERIAL#) values to those in V$SESSION. If it finds an 'Executing' job that doesn’t have a session, it flips TRANSACTION_SYS_LOCAL_TAB.STATE from 'Executing' to 'Error'.
This is a sensible cleanup to do. An 'Executing' job consumes a slot in your background job queue, and if every slot gets filled by an orphan, no jobs can run.
Side note 1:
If you’re running RAC, I’m oversimplifying. If you are, you’ll want to replace V$SESSION with GV$SESSION. If you don’t know whether you are, you probably aren’t.
Side note 2:
Moving from 'Executing' to 'Error' isn’t always sensible in my opinion. When we restart the database, we expect jobs like MRP to start over instead of getting dropped from the queue. That’s why we have this Oracle trigger to put old running jobs back on the queue:
CREATE OR REPLACE TRIGGER c_restart_bgjobs_trg AFTER STARTUP ON DATABASE BEGIN UPDATE ifsapp.transaction_sys_local_tab t SET t.state = 'Posted', t.posted = SYSDATE, t.executed = NULL, t.error_text = NULL, t.progress_info = NULL, t.process_id = NULL, t.started = NULL, t.sid = NULL, t.serial# = NULL, t.inst_id = NULL, t.exclude_cleanup = 'FALSE', t.long_op_id = NULL, t.slno = NULL, t.so_far = NULL, t.total_work = NULL WHERE t.id IN ( SELECT t_.id FROM transaction_sys_local_tab t_ LEFT JOIN gv$session s_ ON s_.sid = t_.sid AND s_.serial# = t_.serial# AND s_.inst_id = NVL(t_.inst_id, 1) LEFT JOIN user_scheduler_running_jobs j_ ON batch_sys.get_job_id_(j_.job_name) = t_.process_id WHERE t_.state = 'Executing' AND t_.queue_id IS NOT NULL AND (t_.procedure_name NOT LIKE 'Transaction_SYS.Process_All_Pending__%' AND s_.sid IS NULL OR (t_.process_id IS NOT NULL AND j_.job_name IS NULL) OR (t_.process_id IS NULL AND (s_.status = 'INACTIVE' OR s_.action <> 'executeDeferredJob')))); COMMIT; transaction_sys.cleanup_executing__; COMMIT; EXCEPTION WHEN OTHERS THEN NULL; END c_restart_bgjobs_trg;
To troubleshoot this issue, I recommend you sprinkle your C_REGISTER_DIRECT_DEL_UTIL_API code with log writes to see where it’s dying.
transaction_sys.log_status_info('We made it to step 1', 'INFO'); transaction_sys.log_status_info('var1_ = ' || var1_, 'INFO'); transaction_sys.log_status_info('We made it to step 2', 'INFO');
(As a best practice, you’d make these messages meaningful enough to be useful to a future developer.)
Unlike SET_STATUS_INFO, LOG_STATUS_INFO runs as an autonomous transaction and will commit even if the session later dies.
Thanks everyone for your feedback and suggestions!
I tried increasing the frequency of the light cleanup job in one of our DEV environments to every two minutes and ran through the process that kicks off the job that keeps getting killed and had no luck. For now we’re going to move the Light Cleanup job to once and hour and see what happens. If the job keeps getting killed we’re going to take @durette ‘s suggestion and sprinkle our code for that API with some log writes to see if we can figure out what’s going on.
Is there a way of automatically excluding a job from the light clean up. We have a job that takes about 90 mins to run. I would rather this job be excluded than have to change the frequency of the clean up.
We have a couple of IAL’s so would rather not affect their performance.