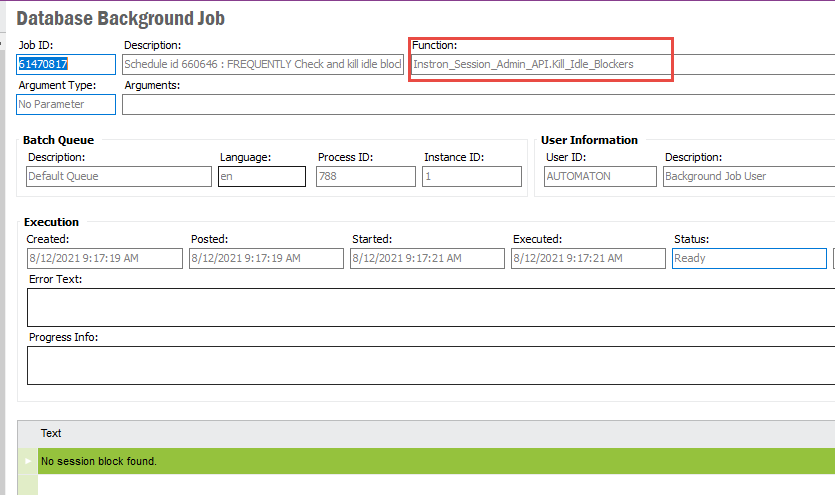
Has anyone had a custom background job killed by a schedule Light Cleanup? The job is marked as “Exclude from Cleanup,” we did this after it happened the first time and thought it would keep it from happening again.
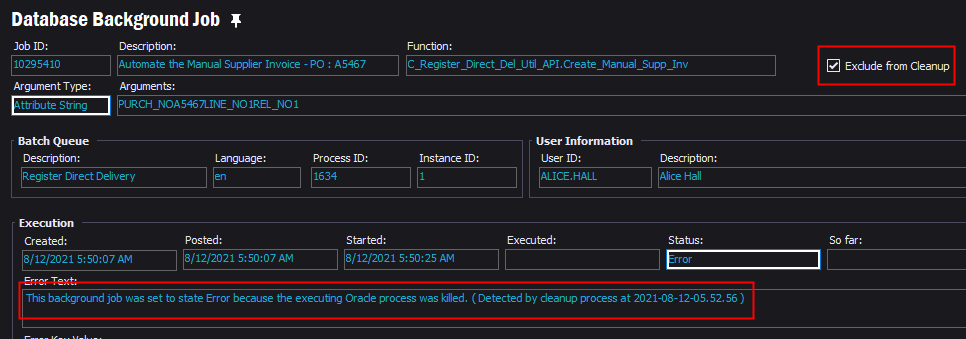
This background job was executed at the exact time listed in the error of the above background job.
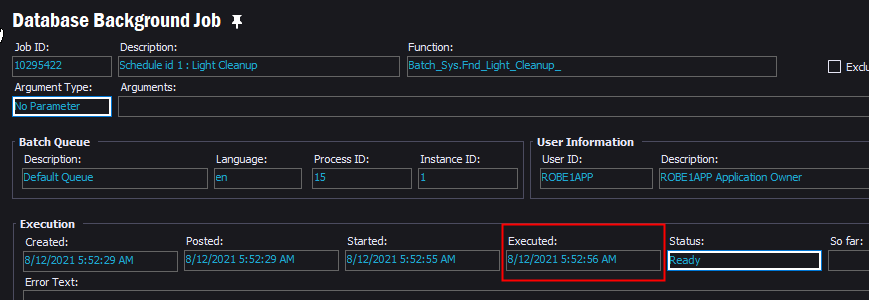
These are in two different queue’s as we’ve moved a majority of our custom jobs into their own to keep jobs processing.
On another note, how often are you running the Light Cleanup job? What’s the suggested time frame?
We are on IFS10 UPD10.