Hi,
I am currently working on a project to simulate a signature handling process relating to customer order deliveries.
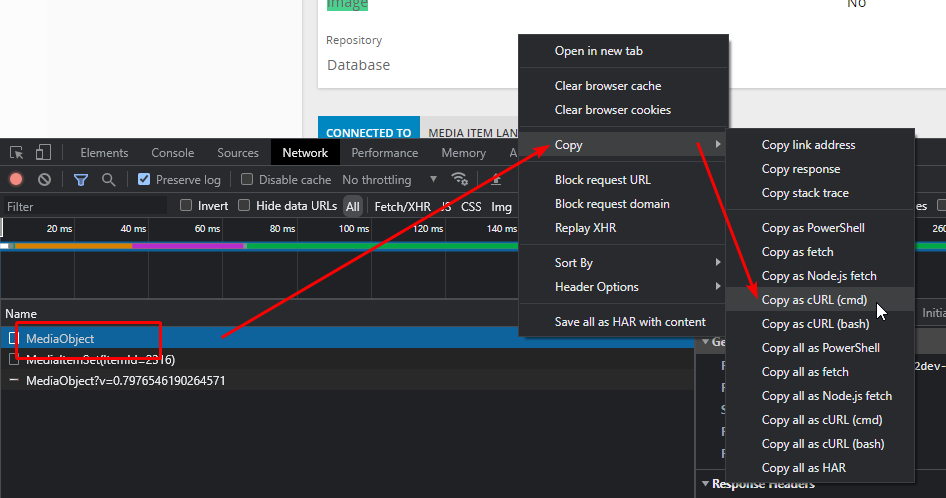
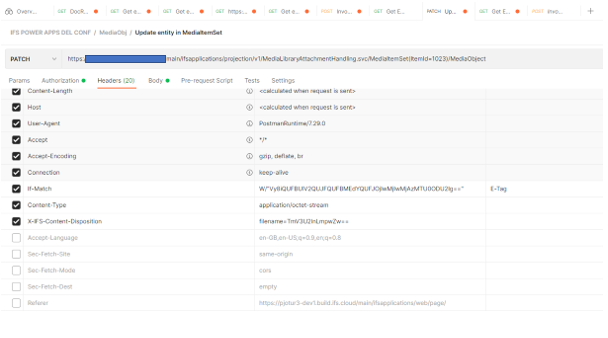
The customer signs for a delivery which marks the order on the IFS Cloud 21r1 platform as delivered but I cannot use the MediaLibraryAttachmentHandling.svc and its end point [PATCH] /MediaItemSet(ItemId={x})
According to Fiddlers traffic logs ( and when a file is inserted via aurena’s UI ).
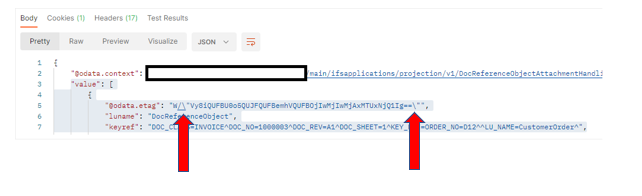
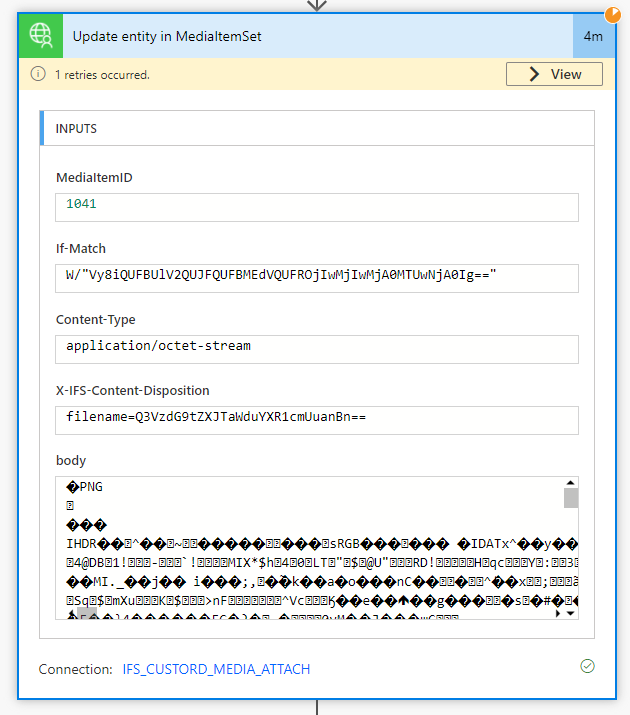
There is an extension of this endpoint ‘/MediaItemSet(ItemId={x})/MediaObject HTTP/1.1’ with RAW data being passed as binary format of a .png image. There is no JSON body being attached as per the IFS API documentation.
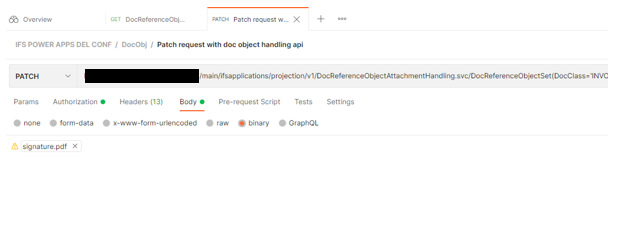
I am stuck at a point where I cannot understand how I can pass binary data in POSTMAN to this same endpoint. The API documentation isn’t providing any example other helpful instructions as to where the binary gets inserted so it can be passed to IFS’s database.
When I copy the application/octet-stream used from the fiddler data, IFS returns a not supported error message.
If I use the JSON body format as the documentation shows, what variable to do I pass the binary data into?
Thanks in advance,
Brian