
We just upgraded our MT OS in a remote cloud with 24R2
After reboot of the OS, the MT is completely out of service: all the pods are in unknow status
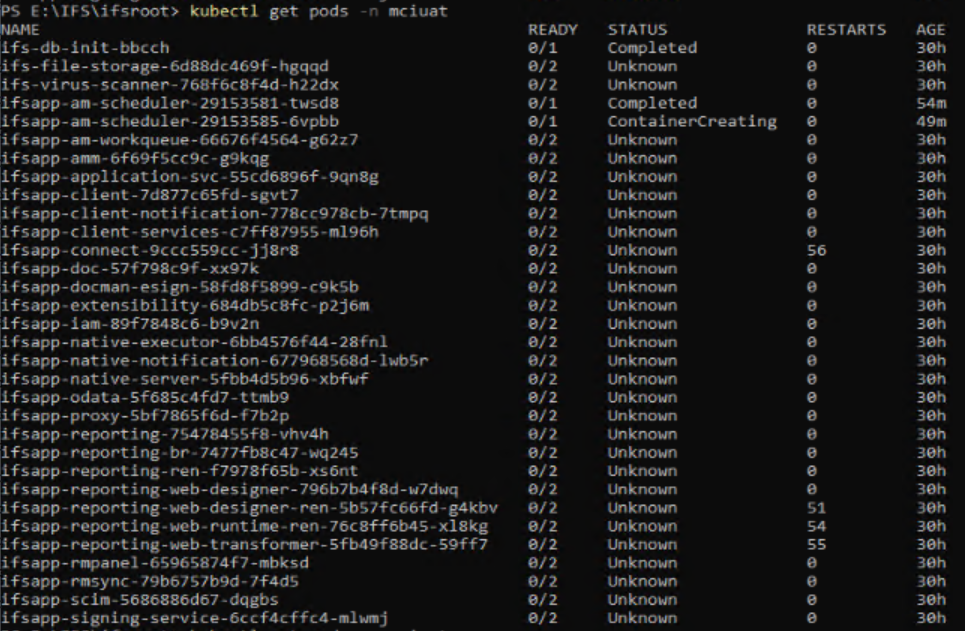
so I went to the procedure of MT delete an MT installer and everything is up and running.
Is there any way to properly shut down the kubernetes pods to avoid this issue ?
Best regards



